
 Data Pump Design and Architecture
Data Pump Design and Architecture
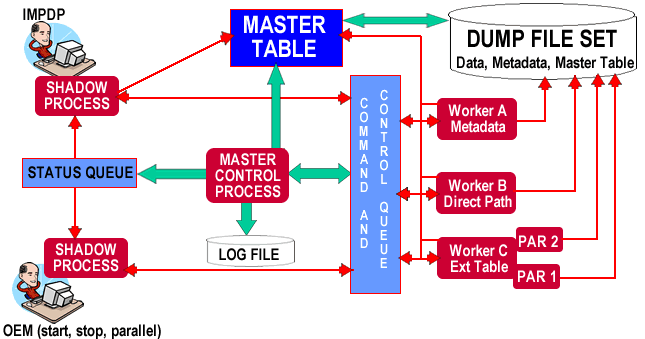
I have created two diagrams that should help us to better understand the Data Pump utility. The first diagram shows all of the components that make up the Data Pump Architecture. The second diagram shows the data flows between the different processes, files and memory areas.
Data Pump Components
Let's take a look at the first
diagram. Data Pump provides four client utilities that execute the procedures
provided in the DBMS_DATA_PUMP PL/SQL package. The client utilities accept input
in the form of parameters which are passed to the DBMS_DATA_PUMP PL/SQL package
to enable the exporting and importing of metadata and data into and out of an
Oracle database.
A brief overview of the four client utilities is provided below:
- EXPDP - Client interface to the Data Pump Export utility. The interface closely resembles its predecessor, Oracle Export.
- IMPDP - Client interface to the Data Pump Import utility. The interface closely resembles its predecessor, Oracle Import.
- OEM Interface - Provides access to the DBMS_DATA_PUMP PL/SQL package from the DB and Grid Control web interfaces.
- Custom Interface - Allows for the movement of complex data mining models.
Because Data Pump is made available through the DBMS_DATA_PUMP PL/SQL package API, users are able to call Data Pump natively from application programs.
Data Access
Methods
Data Pump provides two access methods to load and unload data:
-
Direct Path
- Direct Path unload has been available since Oracle 7.3 and its direct load
counterpart has been around since Oracle 8i. Oracle will attempt to use the
Direct Path first but there are a few situations that can force Data Pump
to switch to the External Tables access method. Oracle documentation provides
a listing of all the reasons why Data Pump was unable to use the Direct Path
data access method. Since Data Pump will automatically switch from the Direct
Path access method to External Tables, it is transparent to the client.
- External Tables - The capability of reading data from external sources has been available since Oracle9i. Oracle10G also support writing data to external destinations. Data Pump provides the ORACLE_DATAPUMP access driver that allows it to read and write to external files. Data Pump is required to use this access method if parallel processing is activated to increase performance.
The user is not required to determine which data access method best fits each job's requirements. The Data Pump utility itself will automatically choose the most appropriate data access method for each table being accessed. No user intervention required! The output created by both the Direct Path and External Table data access methods has the same external format. This allows Data Pump to choose the best access method to load data, regardless of which data access method created the output.
Metadata API
Data Pump uses the DBMS_METADATA package to load and unload metadata. The Metadata
API stores the metadata as XML documents. This differs from the original Export
utility which stored the metadata as DDL. The Data Pump Import utility takes
advantage of the flexibility provided by the XML format by allowing users to
change object ownership, storage characteristics and tablespace destinations.
Data Pump Data
Flow
In order for us to truly understand how data pump works; we need to learn how
the processes and memory structures interact with each other. The second
diagram closely resembles the one that Oracle uses in many of its presentations
on the Data Pump Export data flow. Let's break down the data flow diagram into
its individual components:
Shadow Processes
This should be an easy one for us to understand. The shadow process is the foreground
process that is created when a client logs on to an Oracle database. The shadow
process creates most of the other components found on this diagram. After receiving
the Data Pump initiation request, the shadow process creates the master table,
advanced queue structures for the command and control and status queues and
the master control process.
After the Data Pump job is executing, the shadow process is delegated the responsibility of services the GET_STATUS requests from the client. If the client detaches, the process is no longer needed and is removed. We learned previously that detaching a client from Data Pump does not cause the Data Pump job to stop executing. Users are able to reattach to a Data Pump operation as often as required during the job's life cycle. Each time the reattach is performed, Oracle will start a new shadow process on the client's behalf. In addition, multiple clients can be attached to the same Data Pump job concurrently, with each client having its own shadow process.
Status Queue
Oracle takes advantage of its Advanced Queuing (AQ) feature to provide communication
paths between the different Data Pump processes. The Data Pump master control
process writes work progress and error messages to the status queue. Shadow
processes subscribe to this queue to retrieve the status information.
Master Control
Process
The master control process is the "traffic cop" of the Data Pump environment.
It controls the execution of Data Pump jobs by delegating work requests to worker
processes based on the particular execution phase (metadata capture, data unloading,
data loading, etc.) the job is currently performing. The master control proces
updates the master table with high-level information (job's description, state,
restart and dumpfile info.) required to restart stopped Data Pump jobs. The
process is also responsible for communicating to the clients through the status
queue and performing logging operations.
Master Table
The master table contains information about the details of the current Data
Pump operation being performed. You can equate it to a running log book that
provides information on each object being exported or imported and their locations
in the dumpfile set. In addition, the master table also records the parameters
supplied by the calling program, worker status information and output file information.
The table provides all of the information required to restart a Data Pump job that has stopped because of a planned, or unplanned, failure. The table is owned by the account running the Data Pump job and is written to the dump file at the end of each Data Pump Export operation. Data Pump Import read's the master table and loads it into the user's schema during the initial phase of execution. The table is then used to keep track of the Data Pump Import operation (job status, object being imported, etc.).
Command and
Control Queue
The command and control queue provides an avenue of communications between the
master control process and worker processes. All of the work requests created
by the master process and the associated responses are passed through the command
and control queue.
Worker Process
During the initial phases of a Data Pump job, the master control process creates
worker process to perform the actual data and metadata load and unload operations.
The worker processes are responsible for updating the master table with information
on the status (pending, completed, failed) of each object being processed. This
information is used to provide the detailed information required to restart
stopped Data Pump jobs.
Parallel Query
Process
For those of you that have used Oracle's Parallel Query Option (PQO), these
processes should be familiar to you. Data Pump's Parallel Query Processes are
standard parallel query slave processes that are controlled by the worker process
which assumes the role of the parallel query coordinator.
Dump Datafile
Data Pump dump files are created by EXPDP and used as input by IMPDP. Since
their format is incompatible with their predecessors, Export and Import, the
utilities are not interchangeable. Import can only read a file created by Export
and IMPDP can only read a file created by EXPDP.
The dumpfile contains data and/or metadata and the master table which is written to the dumpfile at the end of each EXPDP operation and read at the beginning of each IMPDP operation.
All of the dumpfile set I/O is generated by Data Pump processes that run within the constructs of the database engine. As a result, the O/S account performing the I/O is Oracle, which usually has a higher level of privileges than most other accounts. Oracle attempts to prevent unwarranted operations from occurring by using Oracle directory objects that require read and write privileges granted by the DBA. Users running Data Pump operations are only able to read and write files in the directories that they have been granted access to.
Before a user is able to run a Data Pump operation, the administrator must pre-create a directory and grant privileges to the user on that directory. This means that users are unable to fully qualify the output file and log file as they were able to do in the non Data Pump versions of Export and Import. If you don't pre-create the directory, Oracle provides a default directory called DATA_PUMP_DIR.
You specify a fully qualified directory on the server when you create the new database directory object and then grant access on that directory to the user running the data pump operation:
CREATE DIRECTORY data_pump_dir1 as '/u03/oradata/datapump';
GRANT READ, WRITE ON DIRECTORY data_pump_dir1 TO foot;
The user running the Data Pump Operation must specify the directory in one of two ways:
By specifying the DIRECTORY parameter on the command line:
EXPDP foot/foot DIRECTORY=data_pump_dir1 dumpfile=users.dmp schemas=eul, kap, mal logfile=users.log
Or by specifying it in the dumpfile and logfile parameters:
EXPDP foot/foot dumpfile= data_pump_dir1:users.dmp schemas=eul, kap, mal logfile=data_pump_directory:users.log
Notice that in the above command I have chosen to write the logfile to a different directory than the Data Pump output file. If you specify the DIRECTORY parameter, the directory specifications embedded in the dumpfile and logfile parameters are optional. Directory specifications embedded in the file parameters override the directory specified in the DIRECTORY parameter.
Up Next
In the next blog, we'll learn how to run the Data Pump Export and Import Utilities.
_____
tags:


{kind=link}
{kind=link}